
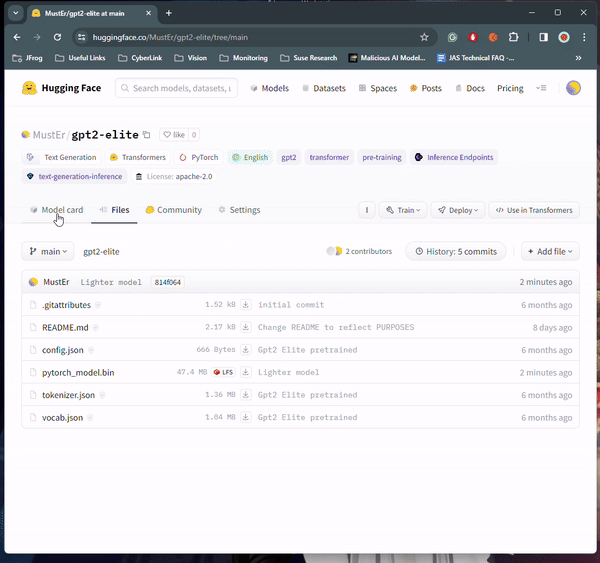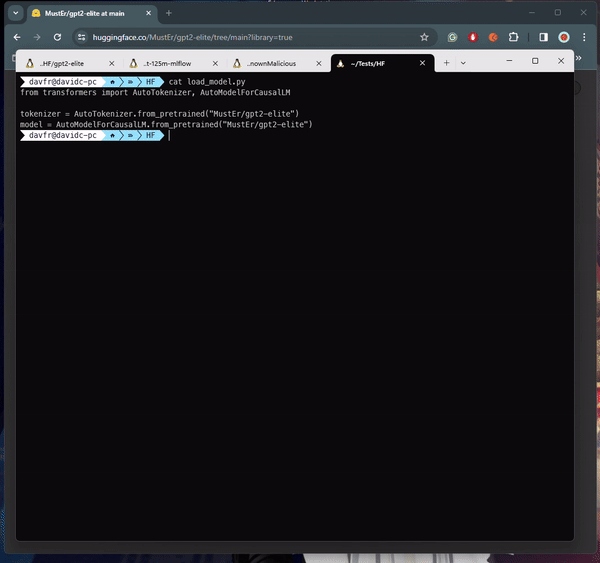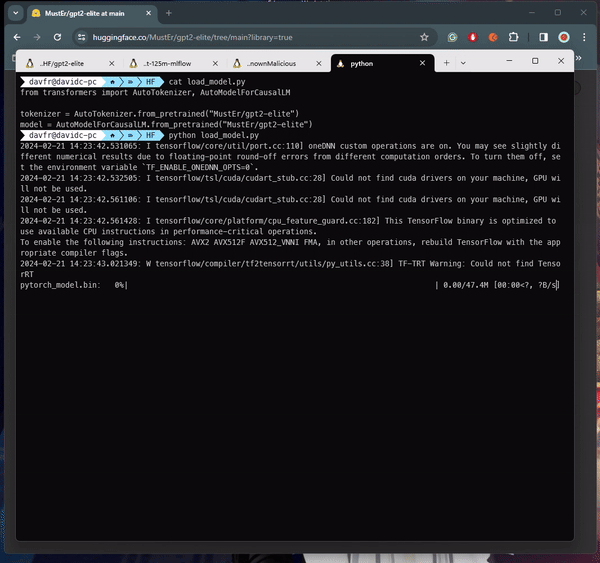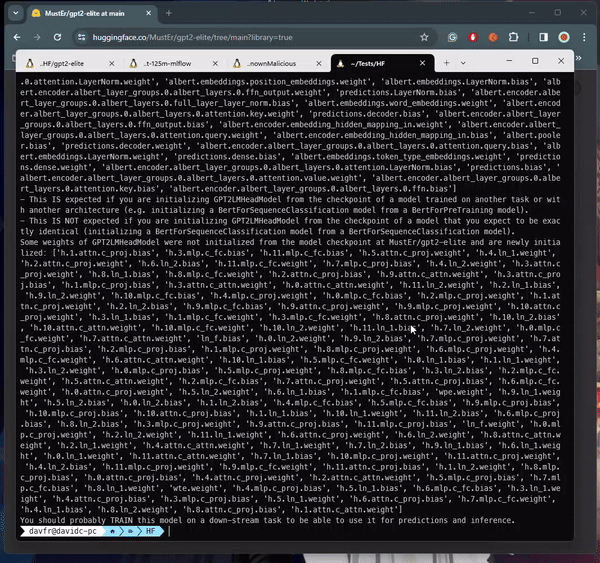
At least 100 instances of malicious AI ML models were found on the Hugging Face platform, some of which can execute code on the victim's machine, giving attackers a persistent backdoor.
Hugging Face is a tech firm engaged in artificial intelligence (AI), natural language processing (NLP), and machine learning (ML), providing a platform where communities can collaborate and share models, datasets, and complete applications.
JFrog's security team found that roughly a hundred models hosted on the platform feature malicious functionality, posing a significant risk of data breaches and espionage attacks.
This happens despite Hugging Face's security measures, including malware, pickle, and secrets scanning, and scrutinizing the models' functionality to discover behaviors like unsafe deserialization.
Malicious AI ML models
JFrog developed and deployed an advanced scanning system to examine PyTorch and Tensorflow Keras models hosted on Hugging Face, finding one hundred with some form of malicious functionality.
"It's crucial to emphasize that when we refer to "malicious models," we specifically denote those housing real, harmful payloads," reads the JFrog report.
"This count excludes false positives, ensuring a genuine representation of the distribution of efforts towards producing malicious models for PyTorch and Tensorflow on Hugging Face."
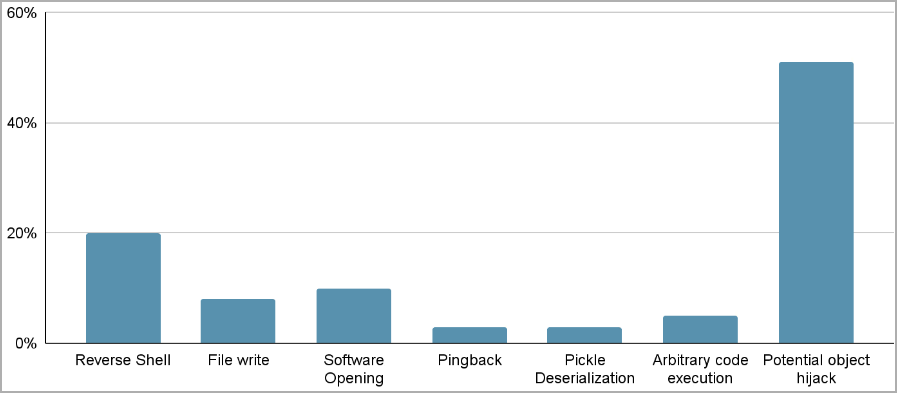
One highlighted case of a PyTorch model that was uploaded recently by a user named "baller423," and which has since been removed from HuggingFace, contained a payload that gave it the capability to establish a reverse shell to a specified host (210.117.212.93).
The malicious payload used Python's pickle module's "__reduce__" method to execute arbitrary code upon loading a PyTorch model file, evading detection by embedding the malicious code within the trusted serialization process.

JFrog found the same payload connecting to other IP addresses in separate instances, with the evidence suggesting the possibility of its operators being AI researchers rather than hackers. However, their experimentation was still risky and inappropriate.
The analysts deployed a HoneyPot to attract and analyze the activity to determine the operators' real intentions but were unable to capture any commands during the period of the established connectivity (one day).
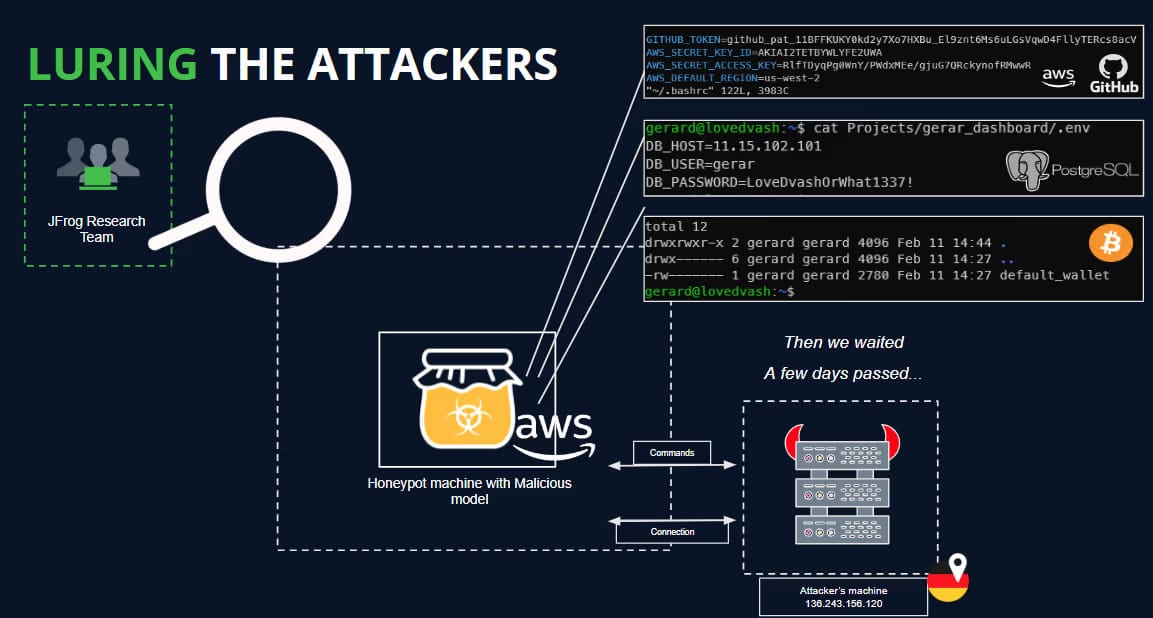
JFrog says some of the malicious uploads could be part of security research aimed at bypassing security measures on Hugging Face and collecting bug bounties, but since the dangerous models become publicly available, the risk is real and shouldn't be underestimated.
AI ML models can pose significant security risks, and those haven't been appreciated or discussed with proper diligence by stakeholders and technology developers.
JFrog's findings highlight this problem and call for elevated vigilance and proactive measures to safeguard the ecosystem from malicious actors.


Comments
sev7en2507 - 4 days ago
Thank you for sharing, I just add where on Reddit we are speaking about: https://www.reddit.com/r/technology/comments/1b37had/malicious_ai_models_on_hugging_face_backdoor/